A Short Introduction to Text Recognition
The text recognition capabilities of AI models have significantly improved in the last few years (and particularly since the widespread introduction of LLMs of the GPT type). These advances apply both to printed texts in obsolete fonts and to handwritten text recognition (HTR, or HWR, i.e., handwriting recognition), thus allowing for the automated transcription of large source corpora. As a result, a steadily growing number of historical sources is made accessible to researchers and the interested public.Aside from researchers from fields such as history, philology or literature studies, many users are researching their family history with the help of Transkribus: https://www.transkribus.org/genealogy That said, the recent success and the marketing hype with exaggerated claims about the potential of consumer ai models, have raised unrealistic expectations, leaving new users disillusioned with the underwhelming first results. The quality of the transcription, as beginners will find out soon, can wildly vary depending on document properties such as language, script or period. Despite all the improvements, accurate text recognition still requires a considerable amount of work to do and time to invest. However, a basic understanding of the operating mode and key functionalities of AI-based text recognition, helps achieve significantly better results. By following a few ground rules, users can develop a workflow specific to the source material they are working on.
There is no such thing as the "best" text recognition model.—The accuracy of AI text recognition, measured in character error rate (CER) and word error rate (WER), depends on the extent to which a model has been trained on source corpora from a specific language, script, style of penmanship, and time period.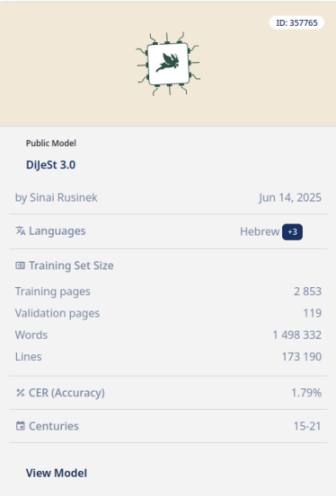
Model card for the Transkribus model DiJeSt3.0, trained on sources in Hebrew, Ladino, and Yiddish (https://app.transkribus.org/models/public/text/dijest-30).
Think of AI text recognition as automation—the AI model compares and identifies patterns based on a) the training data, and b) in case that you use a customized model, on your own transcription work. This (mostly human) groundwork determines the quality of the results at least as much as the inherent predictive power of the AI system.
Know your tools—All text recognition systems have their specific limitations and challenges (see below the sections on Transkribus and Google's Gemini.
Two Approaches
As of January 2026, there are two methodological approaches to tackle the problem of AI text recognition/transcription: Transkribus, the pioneer in AI transcription for researchers, relies on specialist models with a narrow scope: A text model is an AI algorithm that has been trained on a specific set of data, including images and transcriptions. Its purpose is to accurately determine the most likely sequence of characters for each section of handwritten text. There isn't a universal model that applies to all types of handwriting. Therefore, it is essential to choose the most suitable model for the script, language and time period of your documents. (https://help.transkribus.org/automatically-transcribing-your-documents)
The second approach is the one used by the competition: general purpose/multimodal AI models with household names such as ChatGPT or Google Gemini. Trained on a vast amount of data (sometimes of legally grey origin), this model type promises to master a whole range of tasks. The question which model type will prevail—the custom-made model, designed for a specific purpose, or the off-the-shelf all-rounder—has been subject of a long-standing debate in machine learning. In an often cited essay (The Bitter Lesson, 2019), the computer scientist Richard Sutton argues in favour of the generalists: :
The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin. The ultimate reason for this is Moore's law, or rather its generalization of continued exponentially falling cost per unit of computation. [...] One thing that should be learned from the bitter lesson is the great power of general purpose methods, of methods that continue to scale with increased computation even as the available computation becomes very great.Sutton 2019
The scalability of AI applications, Sutton argues, applies particularly to search and learning. The latter includes of course text recognition: According to Sutton, general purpose models trained on extremely large datasets will be more capable of performing complex tasks than specialized models supplied with instructions deriving from previous human experience:
[We] should stop trying to find simple ways to think about the contents of minds, such as simple ways to think about space, objects, multiple agents, or symmetries. All these are part of the arbitrary, intrinsically-complex, outside world. They are not what should be built in, as their complexity is endless; instead we should build in only the meta-methods that can find and capture this arbitrary complexity. Essential to these methods is that they can find good approximations, but the search for them should be by our methods, not by us. We want AI agents that can discover like we can, not which contain what we have discovered. Building in our discoveries only makes it harder to see how the discovering process can be done.Sutton 2019
Sutton can point to the recent two decades of AI development as evidence for his argument: The ImageNet project (2006-2020) achieved a breakthrough in computer vision due to the creation of a visual dataset of unprecedented size.See the project website: ImageNet The introduction of OpenAI's ChatGPT in 2022, was the first large-scale deployment of a chatbot built on the transformer architecture, a concept introduced in 2017.Vaswani et al. 2017 The impressive public success, though, was only made possible thanks to the massive deployment of computational power enabling ChatGPT to devour the better part of the information available on the WWW.
So what does that mean for the (near) future of text recognition? The historian Mark Humphries agrees with Sutton's principle, based on his transcriptions of 18th century handwritten English documents with the help of Google's Gemini model: If we look at how Gemini has improved on English language transcription over time, scaling suggests that you should expect to see similar progress on the documents from your own field over the next months and years. Consider that eighteen months ago, Gemini 1.5 was still getting about 1/5 words wrong, producing what was basically nonsense. Today it is nearly perfectHumphries 2025.
In my experience, the specialized AI (Transkribus) is still ahead of the competition. Then again, I have worked with different source material, mostly early modern documents in Spanish, (Neo-)Latin, and German. The customized Transkribus models, trained on data from the same time and region as my sources, did clearly perform better than general purpose models such as Claude or Qwen (see below). I got similar results when I tried to test the capabilities to handle historical alphabets by submitting samples in pre-1918 RussianThe 1918 reform of the Cyrillic alphabet brought not only the usual spelling differences (as one can find in any language over time) but also typographic changes, most notably the abolishment of four letters. AI systems that are mainly trained on modern Russian texts, are struggling with pre-reform documents. and in 17th-19th century LadinoAlso known as Judaeo-Spanish or Djudezmo, a Romance language spoken by the Sephardic Jews on the Iberian Peninsula and written in a slightly modified version of the Hebrew alphabet.After the expulsion from Spain–ordered by the Catholic Monarchs in the Alhambra Decree (Decreto de la Alhambra or Edicto de Granada) in 1492–Sephardic refugees founded communities in the Ottoman empire, Northern Africa, some European countries, and the Americas. A small Ladino-speaking community flourished also in Vienna until being erased in the Shoah.: Transkribus mantained its pole position with this material as well. But, just as in Humphries' observation regarding English source material, I have noticed that some general-purpose LLMs, Gemini in particular, appear to close the gap. And with some of the Spanish sources, I got the best results by experimenting with a workflow that combined Transkribus for the first step, and Gemini 3 Pro for the corrections (though this might be partly due to the faster response of Google's servers).
Transkribus
Transkribus excels at tasks general LLMs are struggling with, e.g., German Kurrentschrift and its multiple variations. The specific training on historical source corpora pays definitely off and Transkribus models trained on "niche" datasets from, say, the 17th century beat general purpose LLMs that are mainly trained on contemporaneous vocabulary and orthography.
Transkribus started out as a EU-funded project of several European universities (2013); with public fundings eventually running out, the Transkribus team decided to found a cooperative, the community-owned company READ-COOP (Terras et al. 2025). This very distinct business model means a) that the purpose of the company is not to make a profit but to develop and maintain the services offered by TranskribusIn addition to the main AI platform, their activities also include Transkribus Sites
for publishing and sharing text collections, and a scholarship programme., and b) that the community members are the ones who decide on the further development of the platform.As of 2025, the READCOOP website lists over 200 members and co-owners in more than 30 countries, see https://readcoop.org/members. Both institutions and individuals can join: https://readcoop.org/join.
The mission statement outlines the core principles and underscores the importance of the community as the project's main driver:
We come from academia and historical documents are our absolute passion. Think of the wealth of data, knowledge, and stories they contain, slumbering untapped on millions and millions of pages tucked away in archives, libraries, and museums, and in attics, cellars, and shoeboxes all around the world. [...] Transkribus was built not just as a tool, but as a community. By 2019 more than 20,000 people from around the world, from countless fields and with innumerable backgrounds, had signed up, all with the same goal: to make the contents of historical documents accessible. The idea that evolved from this over time was to build the most important platform in historical technology, not as a means of earning profits for shareholders, but to enable stakeholders to collaboratively make every single historical document on the planet accessible. [...] You can train AI models for exactly your materials—and for more than a handful of languages. Everyone can train the AI to recognise exactly their materials in exactly their language. You don’t have to live with the models and results some company decides to give you. [...] We want everyone to have a say in how at least this instance of artificial intelligence is developed and shaped.https://readcoop.org/why-coop
The following is just a brief summary of the workflow with the key features (for detailed information see the guide provided by Transkribushttps://help.transkribus.org/, see also their instruction videos in several languages: https://www.youtube.com/@transkribus/videos.):
- Source Documents
- Transkribus' text recognition processes files in the formats jpeg, pgn, pdf, and IIIF manifest. While image files have a size limit of 10 MB each, PDF files up to 200 MB can be uploaded, which, according to Transkribus, equates to 3,000 pages (https://help.transkribus.org/uploading-files-to-transkribus-overview). The platform recommends a resolution of 300 dpi and suggests that a higher resolution will not entail better results (from my personal experience, processing files in low resolution < 50 MB will likely render flawed transcriptions).READ-COOP, the company that runs Transkribus, sells a special device for producing quality scans with a smartphone: https://www.transkribus.org/scantent & https://www.youtube.com/watch?v=_N7mLfnNf8U.
- Text Recognition v Layout Recognition
- For sources with complex layouts such as multicolumn newspapers with many images or books with marginalia, users can run a separate layout recognition.
- Model Selection
- Users can either choose a fitting model on the Public Model Hub or deploy their own custom model.
- Model Training
- The platform offers also the possibility to train a custom model: "Depending on the type of material and the number of hands, between 5,000 and 15,000 words (around 25-75 pages) of transcribed material are required to start. In general, the neural networks of the Text Recognition engine learn quickly: the more training data they have, the better the results will be. If you are working on printed material, 5,000 words should be sufficient to achieve a good Character Error Rate." https://help.transkribus.org/data-preparation
Interview with Melissa Terras, Professor of Digital Cultural Heritage at the University of Edinburgh and Transkribus co-founder (2025)
Gemini (Google AI Studio)
To get the best out of Transkribus, users have to pick the model best trained on data similar to their sources, and/or they have the option to train a model on their own data. A general-purpose LLM is a different animal. Users cannot modify the model itself, so in order to improve the result, they have to resort to methods such as RAG, adjusting the model settings, and drafting an effective prompt.
Settings of Gemini 3 Pro (Google AI Studio).
References:
- Al-Homoud, Haneen and Asma Ibrahim, Murtadha Al-Jubran, Fahad Al-Otaibi, Yazeed Al-Harbi, Daulet Toibazar, Kesen Wang, Pedro J. Moreno (2025): Cross-Lingual SynthDocs: A Large-Scale Synthetic Corpus for Any to Arabic OCR and Document Understanding. (Pre-print). https://doi.org/10.48550/arXiv.2511.04699 [retrieved Jan 11, 2026]
- Humphries, Mark: Gemini 3 Solves Handwriting Recognition and it’s a Bitter Lesson; Testing shows that Gemini 3 has effectively solved handwriting on English texts, one of the oldest problems in AI, achieving expert human levels of performance. Nov 25, 2025. https://generativehistory.substack.com/p/gemini-3-solves-handwriting-recognition [retrieved Dec 14, 2025]
- Mojtaba Yousefi and Jack Collins. 2024. Learning the Bitter Lesson: Empirical Evidence from 20 Years of CVPR Proceedings. In: Proceedings of the 1st Workshop on NLP for Science (NLP4Science), pp. 175 - 187. Association for Computational Linguistics. https://aclanthology.org/2024.nlp4science-1.15/ [CVPR=Conference on Computer Vision and Pattern Recognition]
- Sutton, Richard (2019): The Bitter Lesson, March 13, 2019 http://www.incompleteideas.net/IncIdeas/BitterLesson.html [retrieved Nov 19, 2025]
- Terras Melissa, Anzinger B, Gooding P et al.: The artificial intelligence cooperative: READ-COOP, Transkribus, and the benefits of shared community infrastructure for automated text recognition. Open Res Europe 2025, 5:16, https://doi.org/10.12688/openreseurope.18747.2
- Vaswani, Ashish and Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin (2017): Attention Is All You Need. https://doi.org/10.48550/arXiv.1706.03762
Software, AI Models, and Repositories:
- Transkribus Public AI Model Hub https://app.transkribus.org/models/public
- Google AI Lab: Gemini API https://ai.google.dev/gemini-api/
- Hugging Face https://huggingface.co/ Model repository
- https://github.com/mhumphries2323/Transcription_Pearl Transcription Pearl
- https://pymupdf.io/ PyMuPDF, Docs https://pymupdf.readthedocs.io; RAG https://pymupdf.readthedocs.io/en/latest/rag.html
- https://pandas.pydata.org/ Pandas ; pandas library: also comes in handy to process data further, e.g. for visualizations https://pandas.pydata.org/docs/user_guide/visualization.html. Pandas works well with Jupyter Notebook https://jupyter.org/
(Jürgen Stowasser)